The Twelve-Factor App

The Twelve-Factor App is a method for creating portable, rapidly deployable, and easily maintainable software-as-a-service apps that can live in the cloud.
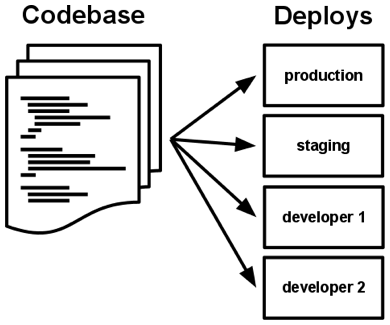
I. Codebase
There is one codebase per app, and it contains all of the code for that app. Shared code across apps is held in libraries that are recorded as dependencies for the app.
The entire codebase, including all versions, are stored in a version control system. Deployments of the app are done from this version control repository. While there is a single codebase, there may be many versions in the codebase, deployed to development, staging, acceptance testing, and production. We might even have A/B versions out in production simultaneously, to test new features.
II. Dependencies
The Twelve-Factor App should not have hidden or implicit dependencies. For our Python servers, we achieve this by:
- Putting all packages needed for running the server in requirements.txt and for developing it in requirements-dev.txt, and
-
Running the server in a
virtualenv that contains just those packages.
(Note: we should set up developer envs with virtualenv as well.)
A great benefit of this explicit declaration of dependencies is that we can set up new developers quickly:
- git clone the repo; and
- pip install -r requirements-dev.txt
III. Config
"Config," or configuration, should be done through environment variables, rather than (separate or changing) configuration files.
The problem with changing a configuration file to, say, use a local web server instead of the production one, is that changing code risks:
- Introducing a typo which breaks something; or
- Forgetting to set the web server back to prod, which breaks everything.
The problem with alternate configuration files is that, as the app grows more complex and more combinations of services are needed, for example, run the developer's Javascript code against the production API server but a staging database, the number of config files undergoes a combinatorial explosion. Environment variables do not have this problem: there is just one setting for each service, file location, etc.
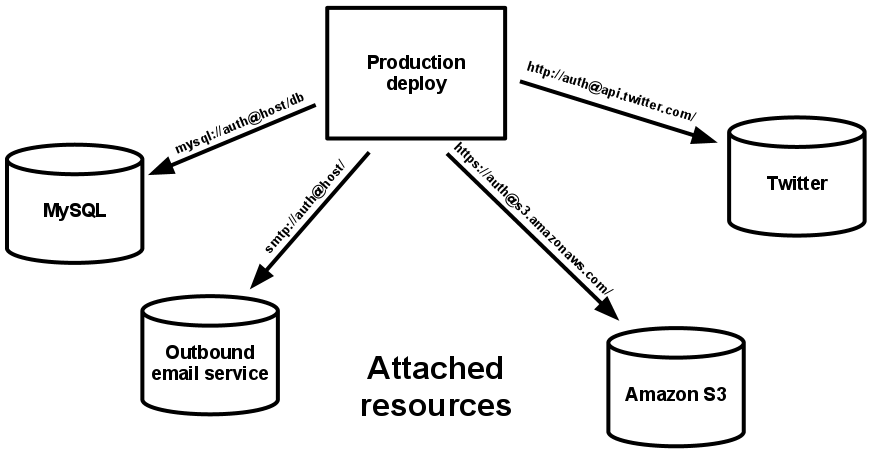
IV. Backing services
Backing services are things like databases, cache managers, mail services, authentication services (like SAML), and messaging systems. These services should be swappable, and the app should be indifferent as to whether they are a local service or a third-party service: they should all be accessed via a URL stored in the config.
V. Build, release, run
We should separate the build, release, and run aspects of our app as strictly as possible.
In our applications, we build by running make prod on the developer's machine. We release through Travis-CI passing the build and pushing it to PythonAnywhere. We can re-run the app at anytime through the PythonAnywhere web interface.
VI. Processes
We should prefer, as far as possible, to run our app in stateless processes. Things like web "sessions" (which we can detect when we leave a web page up for a few minutes and learn "Your session has timed out") should be avoided. Each new interaction with our app should carry all of the information needed to carry out the necessary processing, even if our app has been re-booted in the meantime.
Let's look at the Indra API server as an example of a REST service.
VII. Port binding
The idea here is for the app to be self-contained, and not rely on the addition of some other software for it to function. Export, say, HTTP by binding to a port and handling HTTP requests on that port.
This says that, for instance, our addition of gunicorn to our Heroku deploy should be changed!
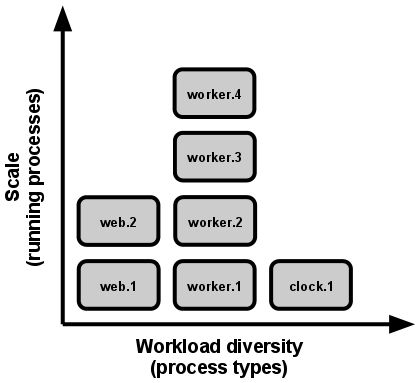
VIII. Concurrency
We scale our app by running additional processes. This is much simpler than adding threads inside a process, and relies on the OSs (already debugged) multitasking.
IX. Disposability
We want the parts of our app to start up quickly and shut down gracefully (not leave any work half done). Quick start up is important, for instance, if we release a new server, discover a serious bug, and need to roll back to the previous version or deploy a new version with the bug fixed. A quick start up assures minimal down time.
We want to be able to bring down servers deliberately, or even have them crash, without disrupting service. (Think of Chaos Monkey.)
X. Dev/prod parity
We try to keep the gap between dev and prod small. We do this in three ways:
- The time gap is small: code goes into production hours or even minutes after it is worked on.
- The personnel gap is small: the developer who wrote the code also manages its release and tracks it in production.
- The tool gap is small: as far as possible, the developer works on the same stack as exists in production. (Question: How do we do this for a PAAS like PythonAnywhere?)
XI. Logs
Logs should be treated as streams to which are fed reports of significant events as they occur. Writing logs to standard output is very flexible: the developer on her laptop can watch the flow of events right on her screen. In production, standard output can be captured by the process that runs the server and can be re-directed as needed, into a file, or perhaps into a log aggregator. In the latter case, multiple servers providing microservices can all feed the same log, giving a better picture of the overall state of the system than would individual logs.
XII. Admin processes
Admin processes are one-off things a developer does to maintain the app, such as a clean up of bad records or a purging of unused logins. The idea here is that admin processes should share as much as possible with the regular app processes: environment variables, library versions, language versions, etc.
In addition, code for admin processes should be in the repo with the app code, and should ship along with it.
The above material is largely drawn from The Twelve-Factor App web site. The image at the top of the page is from the Walters Art Museum in Baltimore, Maryland.