The Modern Software Engineering Way of Work

"Working software is the primary measure of progress." -- The Agile Manifesto
Lesson 1: DevOps as Software Engineering
As software engineers, our aim should be to deliver programs to our users that perform the tasks they need that software to perform. The whole field of software engineering has centered around how to achieve that goal.
One attempt to achieve it was the waterfall model of software development.
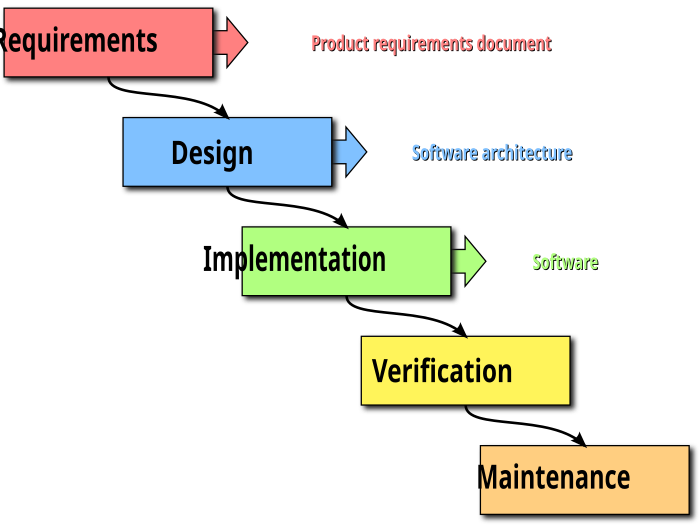
But the waterfall model produced many failures: death marches, instances of the ninety-ninety rule, small matter of programming issues, planning fallacies, and many more such problems. And we can offer a sound diagnosis of why so many waterfall projects failed: the model assumed that all knowledge about a project could be captured by a small group of expert "analysts" right at the start of the project, and the job of the rest of the people involved was just to follow the instructions of those experts, and not to think for themselves. In short, the waterfall model was a species of Taylorism.
Of course, some software projects using the waterfall model succeeded. But it turns out that most successful software projects, over many decades, instead followed the "UNIX philosophy", where development projects sought to quickly achieve an MVP, and then proceeded to improve that initial product with incremental changes.
The recognition of this fact lead, over time, to the formulation of the Lean and Agile development methods. These methods focused on rapidly creating and releasing to users incremental improvements in a software. (Please take the time to read the Wikipedia pages linked to above on Lean and Agile: you are responsible for knowing that material.) The advantages of small improvements to a software product, released frequently, include:
- Value is delivered to the users quickly, rather than waiting for "release 2.0" for the users to get a hold of the features they need.
- Small batches can more easily be tested and verified as working properly.
- If a small release contains an error, it is easier to roll it back than it is to roll back a major release.
- The "feedback loop" between users and programmers is shortened, allowing programmers to learn about users' needs more rapidly, and respond more quickly to them.
- Greater programmer satisfaction, as programmers can regularly see the value of their work to their users.
As development teams adopted Lean and Agile methods, they often became capable of producing production-ready software on a daily basis, or even more frequently. (For instance, Amazon releases software into production once every 11 seconds, on average.) But this created a problem: managing software in production environments was traditionally the job of operations, not of the developers. And operations viewed its job as slowing the pace of releases, because releases meant bugs, crashes, and other problems operations had to handle.
How could this gulf between development and operations be narrowed? A few forward-thinking operations people saw a way to reconcile the aims of development and operations: operations itself had to become Lean and Agile! In particular, rather than hand-provisioning operations infrastructure, operations team members had to themselves become coders, and apply the full toolkit of Lean and Agile methods to operations: incremental changes, automated testing, source code control, automated builds, and so on. One of those operations people, Patrick Debois, named a conference DevOpsDays, and from that seed, the term "DevOps" spread.
As a result, the term "DevOps" is an umbrella beneath which reside a large number of methods and tools. We can better understand why each of the areas we will studying falls under "DevOps" when we comprehend how they contribute to the DevOps goal of delivering useful and correct software to users as rapidly and as often as possible. Let's look at how the main areas of DevOps contribute to this goal:
- Testers cannot test successfully unless they are part of the production process from day one: thus, continuous testing.
- Operations cannot successfully deploy constantly evolving products unless deployment itself becomes a software product capable of swiftly evolving: thus, software as infrastructure.
- The "business" stakeholders in the product can't ensure it is meeting business needs unless they are continually engaged: thus continual interaction between the engineers and the "business people."
-
Why is "business" in scare quotes above?
"We are not developing software. We are doing something larger and software is just part of the solution." -- Tom Poppendieck - How new versions of a piece of software impact the end users cannot be determined without continual feedback from those users, thus:
- Incremental development, which means developers work on small batches and can easily change course based on feedback;
- Continuous deployment, allowing users to comment on the work done in those small batches; and
- Continuous monitoring, so that problems using the product become known right away.
At this point in our course, you should read the Wikipedia page on DevOps. And watch:
Lesson 2: My DevOps Story
Or how, being weaned on nutritious Bell Labs commonsense, and having dined on Oakeshott's critique of rationalism, I was ready to digest the DevOps feast.
I began my career as a software engineer working on MS-DOS computers in the mid-1980s. But before the decade was over, I had begun working on UNIX platforms. As I came to appreciate the elegance of the UNIX programming environment, I sought out the writings of the people who had been instrumental in its creation. This was the tremendous group of software engineers assembled in Bell Labs from the late 1960s through the early 1980s, including Ken Thompson, Dennis Ritchie, Brian Kernighan, Alfred Aho, Peter Weinberger, Bjarne Stroustrup, Jon Bentley, and P.J. Plauger. From them I learned a pragmatic, incremental style of developing software. Rather than pursuing some grand, abstract vision, I learned to deliver minimal but working software to users as regularly as possible, and to learn from user feedback what further features needed to be added.
By the 1990s, I had learned enough that I felt ready to make my own contributions to this literature, writing "Semiotics and GUI Design," pioneering intranets as a way of delivering in-house software, touting infrastructure as code, describing generic client-server interfaces, stressing the basics of OOP, and more.
Subsequently, in a decade away from software engineering, I conducted extensive studies on rationalism. These studies prepared me to understand development methods like the waterfall model as examples of "dreaming of systems so perfect that no one will need to be good"* -- these practitioners were practicing "rationalism in software engineering." Or, to put it in my colleague Nassim Taleb's terms, these systems were designed to be robust, impervious to change. (Consider the desire to "lock down" the software's feature set in the requirements phase of the waterfall model.) What was needed instead were systems that were antifragile, and actually thrived on change.
Thus, when I returned to software engineering and came across the DevOps movement, my experience was not one of meeting someone brand new, but of re-acquainting myself with an old friend who was sporting a new look, and had learned some fancy new tricks since we had last met. In particular, the DevOps approach does not try to ensure design is 100% complete before any code is written: an impossible, rationalist dream. The DevOps approach does not attempt to ensure all software leaving a developer's hands is bug-free: again, an impossible, rationalist dream. And it does not attempt to ensure that all released software is 100% crash-free and secure. Instead, the DevOps approach recognizes that humans are fallible and errors will occur, and so stresses fast recovery from errors and a low-blame culture that emphasizes learning from errors rather than punishing transgressors. So, for instance, rather than blaming the programmer who released a piece of buggy code into production, the DevOps approach asks, "What test haven't we written that would have caught that bug before release?"
* T.S. Eliot, "Choruses from the Rock"
Lesson 3: DevOps and the Division of Labor
Leonard E. Read began his famous essay “I, Pencil” (here) by noting:
I, Pencil, simple though I appear to be, merit your wonder and awe, a claim I shall attempt to prove… Simple? Yet, not a single person on the face of this earth knows how to make me. This sounds fantastic, doesn't it? Especially when it is realized that there are about one and one-half billion of my kind produced in the U.S.A. each year.
Read goes on to list just a few of the many, many people who contribute to the making of a “simple” pencil: loggers, miners, makers of chain saws, hemp growers, the manufacturers of railroads and railroad cars, millworkers, producers of precision assembly-line machines, the harvesters of canola seed, farmers growing castor beans, and more.
What Read is praising in his essay are the benefits of the division of labor, the economic process through which a human community, by dividing up tasks and “assigning” various members to specialize in each task, can greatly increase its output. (I put “assigning” in scare quotes because, in a market economy, for the most part people are not literally assigned to tasks, but instead choose their roles in the division of labor based upon their talents and the prevailing compensation for each possible role they could fill.) The benefits of the division of labor were, of course, recognized at least as far back as Plato and Xenophon. As Plato put it in The Republic, “Well then, how will our state supply these (physical) needs? It will need a farmer, a builder, and a weaver, and also, I think, a shoemaker and one or two others to provide for our bodily needs. So that the minimum state would consist of four or five men.” And Adam Smith famously expounded upon those benefits in The Wealth of Nations, writing “The greatest improvement in the productive powers of labour, and the greater part of the skill, dexterity, and judgment with which it is anywhere directed, or applied, seem to have been the effects of the division of labour” (The Wealth of Nations). Smith goes on to describe the production of pins, a task at which a single person, not specialized at the task, “could scarce, perhaps, with his utmost industry, make one pin in a day, and certainly could not make twenty” (same source as above). But, when ten workers took on specialized tasks, with the help of specialized machinery, though “they were very poor, and therefore but indifferently accommodated with the necessary machinery, they could, when they exerted themselves, make among them about twelve pounds of pins in a day” (same source), with the result that each worker produced several thousand times the number of pins per day as would have been possible without the division of labor.
In the early 20th century, this method of increasing productivity was pushed to its limits. Tasks were broken down to the extent that workers with minimal skills could be assigned simple, highly repetitive actions, and perform them with almost no knowledge of what anyone else on the assembly line was up to. Although this led to higher output of standardized products, the disadvantages of extending the division of labor to this extent were not overlooked. Karl Marx noted that the extensive division of labor alienated the worker from the product he was producing: someone who spends all day tightening a particular lug nut may be little able to associate what they do with “making a car.” But even Adam Smith, who, as we have seen, praised the effects of the division of labor, commented:
In the progress of the division of labour, the employment of the far greater part of those who live by labour, that is, of the great body of people, comes to be confined to a few very simple operations, frequently to one or two. But the understandings of the greater part of men are necessarily formed by their ordinary employments. The man whose whole life is spent in performing a few simple operations, of which the effects are perhaps always the same, or very nearly the same, has no occasion to exert his understanding or to exercise his invention in finding out expedients for removing difficulties which never occur. He naturally loses, therefore, the habit of such exertion, and generally becomes as stupid and ignorant as it is possible to become for a human creature to become. (http://www.econlib.org/library/Smith/smWN20.html#V.1.178)
Smith is pointing out a general problem with the extensive division of labor, but there is a much more particular problem, which only came to prominence in the recent days of increasing automation and increasing demand for innovative and customized products: the sort of mindless, production-line division of tasks common in mid-20th-century factories created a workforce downright discouraged from thinking about how their work fit into the production process as a whole, or how alterations in other parts they did not directly make might affect their own task. Such a holistic view was only supposed to be required of the engineers who designed new products or who designed the factory processes that would produce those new products. As in a planned, socialist economy, all knowledge about the product and the production process would be concentrated at the top of a pyramid of work, and those below the peak were to just mindlessly follow the orders of those knowledge commissars.
A major problem with this approach is that as products become more complicated and the pace of innovation increases, no single mind, or even a small group of minds, is capable of grasping all of the interconnections between the different parts of those complex products, and thus, cannot foresee how an innovation supposedly concerning only one part will actually have ripple effects on many other apparently separate production tasks. This fact was realized quite early at Toyota, and led to the invention of the Toyota Production System, the forerunner of Lean Software Development. As Mary and Tom Poppendieck note in Implementing Lean Software Development:
Toyota’s real innovation is its ability to harness the intellect of “ordinary” employees. Successful lean initiatives must be based first and foremost on a deep respect for every person in the company, especially the “ordinary” people who make the product or pound out the code. (pp. 124-125)
As important as these ideas were in factory production, their importance is even greater in the world of software development, where production is always production of a novel product: otherwise, one would simply buy or rent an existing software product, which is almost always a lower cost venture than “rolling your own.”
In such an environment, it is simply not possible to assign the “workers” (programmers) a simple, repetitive task, and expect them to achieve decent results without at least some understanding of the overall product design, as well as an understanding of how their particular “part” integrates with the other parts of the product as a whole. In such a situation, worker obedience no longer “works.” A manager cannot tell a software engineer working on a product of even moderate complexity to just follow the manager’s orders: the programmer can bring production to a halt simply by asking, “OK, what line of code should I write next?”
But further: no knowledge worker producing an even moderately complex product can do his work properly without his understanding of his part in the production process evolving in continuous interaction with the evolving understanding of all of the other knowledge workers producing the product: one such worker gaining a better understanding of the nature of her component simply must convey that understanding to all other workers upon whom the changes in her component have an impact, and that set of workers typically encompasses almost everyone working on the product. As the Disciplined Agile Framework has it:
Enterprise awareness is one of the key principles behind the Disciplined Agile (DA) framework. The observation is that DA teams work within your organization’s enterprise ecosystem, as do all other teams. There are often existing systems currently in production and minimally your solution shouldn’t impact them. Better yet your solution will hopefully leverage existing functionality and data available in production. You will often have other teams working in parallel to your team, and you may wish to take advantage of a portion of what they’re doing and vice versa. Your organization may be working towards business or technical visions which your team should contribute to. A governance strategy exists which hopefully enhances what your team is doing.
The various aspects of Agile / Lean / DevOps production follow from recognizing these realities concerning knowledge workers cooperating to create innovative products. Programmers cannot do their jobs in isolation: thus, the practice of continuous integration, which quickly exposes mutual misunderstandings of how one person’s work impacts that of others. Testers cannot test successfully, without introducing large delays in deployment, unless they are part of the production process from day one: thus, continuous testing, guaranteeing that product flaws are exposed and fixed at the earliest moment possible. Operations cannot successfully deploy constantly evolving products unless deployment itself becomes a software product capable of evolving as fast as the products of the developers: thus, software as infrastructure. The “business” stakeholders in the product cannot ensure the product is really meeting business needs unless they are continually engaged in the development process: thus continual interaction between the engineers and the “business people.” How new versions of a piece of software impact the end users cannot be determined without continual feedback from those users: thus, incremental development, which means developer work on small batches and can easily change course; continuous deployment, allowing end users to comment on the work done in those small batches; and continuous monitoring, so that any problems using the product become known almost as soon as they occur.
Given the above realities, a rigid division of labor hinders businesses from responding agilely to changing market conditions while producing software. If workers are confined to narrow silos based on job title, the interaction between the many components of a complex piece of software must be defined from the top down, and this restriction will result in a very limited capacity to deviate from an initially defined pattern of interaction. In Disciplined Agile, it is noted:
IT departments are complex adaptive organizations. What we mean by that is that the actions of one team will affect the actions of another team, and so on and so on. For example, the way that your agile delivery team works will have an effect on, and be affected by, any other team that you interact with. If you’re working with your operations teams, perhaps as part of your overall DevOps strategy, then each of those teams will need to adapt the way they work to collaborate effectively with one another. Each team will hopefully learn from the other and improve the way that they work. (
Let us consider a realistic change that might hit a project mid-stream, and just a few of the areas it might impact.
I was once developing an option-trading package for a team of traders. At first, we were only getting quotes for options from a single exchange. The traders realized that they wanted instead to see the best bid and ask from every exchange, which meant we needed to get quotes from four exchanges, not one. This might seem to be a specification change with a narrow scope: just add three more price feeds to the application. Who would this concern beyond the programmer who would be adding the feature?
Well, for one, it would concern the team supporting the price server: this was going to quadruple the load this application would place on it. It was also going to impact the order server: that server had to be prepared to send orders out to the proper exchanges. Oh, and the testing team had better be prepared to simulate quotes coming in from four sources, not one. Also, the monitoring team would have to detect if there was a lag on quotes arriving from four sources, not one.
Or consider the patterns and tales from Michael T. Nygard’s book, Release It!. Continually, in Nygard’s stories, solving a problem in a sophisticated web operation involves a wide range of both technical and business knowledge. For instance, in terms of designing “circuit breakers” that limit the impact of the failure of one component, Nygard notes that deciding what to do when a circuit breaker trips is not merely a technical decision, but involves a deep understanding of business processes: “Should a retail system accept an order if it can’t confirm availability of the customer’s items? What about if it can’t verify the customer’s credit card or shipping address?” (p. 97) Later in the book, a retail system went down entirely on Black Friday, costing his client about a million dollars an hour in sales. Fixing the problem involved understanding the functioning of the frontend of the online store, the order management system, and the scheduling system, and the interactions of the three.
A software engineer who thinks of his job narrowly, as just being responsible for writing the code to do the task he is told the code should do, is not going to be thinking of the multiple other areas this change would affect. And a higher-level designer is unlikely to know enough of the details of all of these areas to fully understand the impact of this change: the best bet for being able to successfully respond to this changed business requirement is for the people working in each specialization also to have a vision of the overall system, an understanding of how other specialized areas function, and to have robust communication channels open between the various specialties: in other words, to break down the silo walls produced by a rigid division of labor, and embrace agile development principles. Or, as said in Disciplined Agile:
However, to succeed delivery teams must often work with people outside of the team, such as enterprise architects, operations engineers, governance people, data management people, and many others. For agile/lean delivery teams to be effective these people must also work in an agile/lean manner.
Lesson 4: Software Development as a Discovery Procedure
Nobel-Prize-winning economist F.A. Hayek was one of the most significant social theorists of the 20th century. He did important work on the theory of the business cycle, on monetary theory, on the theory of capital, on the informational role of market prices, on the nature of complex phenomena, and on the importance of group selection in evolution.
Hayek's work has important insights to offer those advancing Lean / Agile / DevOps ideas for IT. Here I will focus on his paper "Competition as a Discovery Procedure," and note how similar Hayek's vision for the role of competition in the market is to the Agile understanding of the importance of the "development" part of the phrase "software development."
That essay of Hayek's was written in response to the model of "perfect competition" that had come to dominate economics in the middle of the 20th century. In that model, "competition" meant a state of affairs in which each market participant already knew every relevant detail about the market in which they participated, and thus simply "accepted" a price that, somehow, mysteriously emerged from the "given data" of their market. In such a situation no actual competition, as it is commonly understood, really occurs: every "competitor" already knows what product to offer, what price to charge, and simply passively accepts their situation as it stands.
Similarly, the waterfall model of software development simply assumes that what has to be discovered, in the process of software development, is already fully known at the start of the process. Instead of correctly understanding development as a process through which the analysts, coders, testers, documenters, and users come to a mutual understanding of what the software should really be like, the waterfall model posits that certain experts can fully envision what the final product should be, right at the start of the process. "Software development" then consists of these experts drawing up a document analogous to one of the "five-year plans" of the Soviet Union, detailing how all of the other "participants" should work, according to the experts' plan. No further input is needed as far as what the software being "developed" should actually do. But in reality, as Eric Evans notes:
When we set out to write software, we never know enough. Knowledge on the project is fragmented, scattered among many people and documents, and it's mixed with other information so that we don't even know which bits of knowledge we really need. Domains that seem less technically daunting can be deceiving: we don't realize how much we don't know. This ignorance leads us to make false assumptions. (Evans, p. 15)
Hayek, describing the dependence of economists on the perfect competition model, admits:
It is difficult to defend economists against the charge that for some 40 or 50 years they have been discussing competition on assumptions that, if they were true of the real world, would make it wholly uninteresting and useless. If anyone really knew all about what economic theory calls the data, competition would indeed be a very wasteful method of securing adjustment to these facts. (Hayek, 179)
He goes on to write:
In sports or in examinations, no less than in the world of government contracts or prizes for poetry, it would clearly be pointless to arrange for competition, if we were certain beforehand who would do best... I propose to consider competition as a procedure for the discovery of such facts as, without resort to it, would not be known to anyone... (Hayek, 179)
This, I suggest, is quite analogous to software development: it would be pointless to engage in such a time-consuming, mentally challenging activity if we knew in advance what software "would do best." We engage in software development to discover "such facts as, without resort to it, would not be known to anyone." It is only when we put our interface in front of real users that we find out if it really is "intuitive." It is only when we confront our theoretical calculations with the real data that we know if we got them right. It is only when we put our database out to meet real loads that we can tell if its performance is adequate. We can only tell if our CDN design meets our goals when it actually has to deliver content. None of this means that we should not plan as much as possible, in advance, to make sure our software is up to snuff, just that how much is possible is quite limited.
Hayek highlights the true value of competition in the following passage:
[C]ompetition is valuable only because, and so far as, its results are unpredictable and on the whole different from those which anyone has, or could have, deliberately aimed at... We do not know the facts we hope to discover means of competition, we can never ascertain how effective it has been discovering those facts that might be discovered... The peculiarity of competition -- which it has in common with scientific method -- is that its performance cannot be tested in particular instances where it is significant... The advantages of accepted scientific procedures can never be proved scientifically, but only demonstrated by the common experience that, on the whole, they are better adapted to delivering the goods than alternative approaches. (Hayek, 180)
Bjarne Stroustrup, the creator of C++, has very similar things to say about programming:
When we start, we rarely know the problem well. We often think we do... but we don't. Only a combination of thinking about the problem (analysis) and experimentation (design and implementation) gives us the solid understanding that we need to write a good program... It is rare to find that we had anticipated everything when we analyzed the problem and made the initial design. We should take advantage of the feedback that writing code and testing give us (Stroustrup, 178).
Given that competition is a discovery procedure, and thus we can't ever predict, with certainty, the results of market competition, Hayek considers what sort of predictions economists can make, if any? After all, if economics is a science, we expect it to say at least something about the course of events. Hayek concludes that:
[The theory of the market's] capacity to predict is necessarily limited to predicting the kind of pattern, or the abstract character of the order that will form itself, but does not extend to the prediction of particular facts. (Hayek, 181)
Similarly, in software development, although we can't anticipate in advance exactly what lines of code will be needed... or development would be done!... we can anticipate that good software will exhibit certain patterns. And thus we see Hayek anticipating the "pattern language" approach to software development that was imported from the architectural works of Christopher Alexander into software development.
Let us turn aside from contemplating the market order, upon which Hayek focuses most of his attention, and consider the other order Hayek mentions: science. Although any scientific enterprise involves planning, we cannot possibly plan out in advance what discoveries we will make in the course of some scientific research: if we knew those, we would have already discovered them, and our research would be done: we would just be writing up the results. But that is precisely what the waterfall model supposes: we already know what the software in question must do: development is complete, and all that remains is to turn the requirements into an executable program: essentially, just "writing up the results." This approach actually blocks the process of discovery, as it leaves no room for the developers or the users to achieve new realizations in the process of turning the blueprint into working code, realizations that would expose the "specs," the master plan, as being based upon false hypotheses.
One aspect of recognizing an order as a discovery procedure is the implication that where in an organization the most relevant discoveries will be made is also not predictable in advance. Many scientific discoveries have been made because a lab assistant failed to follow some accepted procedure, or noticed something her "betters" had missed. And many successful market innovations arose at the level of the factory floor or the sales visit, and not in the executive suite.
The waterfall model assumes that every insight about the proper form of the final software product will come from the "analysts," and that it is the job of "the workers," such as programmers, to simply turn those insights into executable code. In this respect, the waterfall model has much in common with "Taylorism," the blueprint for mass production pioneered by Frederick Taylor around the turn of the last century. As Jerry Muller describes it:
Taylorism was based on trying to replace the implicit knowledge of the workmen with mass production methods developed, planned, monitored, and controlled by managers. 'Under scientific management,' [Taylor] wrote, 'the managers assume... the burden of gathering together all the traditional knowledge which in the past has been possessed by the workmen and then of classifying, tabulating, and reducing this knowledge to rules, laws, formulae... Thus all of the planning which under the old system was done by the workmen, must of necessity under the new system be done by management in accordance with the laws of science. (Muller, pp.32-33)
But Taylorism and similar top-down approaches proved inadequate in manufacturing, as demonstrated by the triumph of the Toyota Production System, just as top-down planning failed in the Soviet Union, and just as it does in science. Perhaps their most important piece of wisdom contained in the Lean / Agile / DevOps movement is that the waterfall model of software development fails for very similar reasons.
Once we recognize software development is a discovery procedure, it should prove useful to categorize some of the features of a program that are most likely to be discovered in the actual process of development, rather than having been perfectly anticipated in our initial analysis of our users' requirements. What I offer here is only intended as an initial cut at what surely is a much more extensive list that could be developed. With that caveat in mind, in the process of actually developing software, here are some likely areas where our initial analysis will fall short of the mark:
- We will discover "corner solutions" we had not anticipated. Corner solutions are extreme cases that are not easy to detect in the analysis phase, such as a buyer who has purchased every single product the company sells (what do we market to her?), or a security the price of which has dropped to zero (were we dividing by that price at some point?).
- Some aspect of the user interface that was "obvious" to the designers will appear completely obscure to the actual users: we won't know this until we put some working software in front of them.
- A calculation or algorithm that the users thought was adequate to their purposes actually is not: it may have handled a few common cases correctly, but once exposed to real world data, its shortcomings may become obvious.
- Some part of the system may incur a load that was not anticipated during the analysis phase: a particular feature may be much more popular than was predicted, and the capacity of the components assigned to handle that feature might be swamped.
- There may be regulatory/legal requirements for the software that the users interviewed by the analysts simply took for granted, the violation of which will only become apparent when those users are faced with a working version of the software.
- "Black swan" events will arise in the course of development: a market crash, a new, unforeseen law, a brand-new market emerging, a natural disaster, or a security threat. When we delay as many decisions to as late a time as possible, rather than trying to make all significant choices up front in an "analysis phase," we are far more flexible in responding to such events. As Nassim Taleb wrote, "once we produce a theory, we are not likely to change our minds -- so those who delay developing their theories are better off" (Taleb, 144).
Bibliography
Domain-Driver Design: Tackling Complexity in the Heart of Software, Eric Evans, Addison-Wesley, Upper Saddle River (New Jersey), 2004.
"Competition as a Discovery Procedure," in New Studies in Philosophy, Politics, Economics and the History of Ideas, F.A. Hayek, University of Chicago Press, Chicago, 1978.
Programming: Principles and Practice Using C++, Bjarne Stroustrup, Addison-Wesley, Upper Saddle River (New Jersey), 2014.
The Tyranny of Metrics, Jerry Z. Muller, Princeton University Press, Princeton, 2018.
The Black Swan, Nassim Nicholas Taleb, Random House, New York, 2010.
Lesson 5: Anti-Fragile Chaos Monkeys
On April 21, 2011, "A rare and major outage of Amazon's cloud-based Web service... took down a plethora of other online sites, including Reddit, HootSuite, Foursquare and Quora" ( CNN Money). Nevertheless, Netflix, one of Amazon's largest cloud customers, did not crash. This led to suspicions that Amazon had somehow favored Netflix at the expense of smaller customers (source: The DevOps Handbook?). In response to those suspicions, Netflix engineers published a paper on their " Chaos Monkey," a program Netflix developed that would be like the entry into their data center of a monkey that "randomly rips cables, destroys devices and returns everything that passes by the hand [i.e. flings excrement]. The challenge for IT managers is to design the information system they are responsible for so that it can work despite these monkeys, which no one ever knows when they arrive and what they will destroy" ( Chaos Monkeys).
By deliberately creating a program that would wreak havoc in their production environment, Netflix engineers made their system antifragile: rather than resisting the idea that their systems might be subject to extreme events, they assumed their systems would be... in fact, they deliberately created such extreme events, and demanded that application developers engineer their systems to "learn" from such stressors and become stronger as a result of facing them.
So what does it take for a system to become "antifragile"? Well, for one thing, it must exhibit "optionality": a system that totally commits itself to a single way of proceeding (like the Waterfall Model in its analysis phase) cannot respond to Black Swan events, since they are by definition unexpected. Instead of trying to precisely predict (where "precisely" may include precise probabalistic estimates) what will occur, we construct our system to "learn" from Black Swans and grow stronger from their occurence. (Within limits, of course: if a meteor hits our data center and also destroys all data centers within our hemisphere, we probaly cannot become stronger in response to that event.)
One aspect of "antifragility" is "optionality." That means keeping as many options for action open as long as possible. This clearly connects to the Lean principle of deferring commitment. By delaying our choices as to a course of action, a technology, a design pattern, etc., as long as possible, we leave ourselves open to respond to new circumstances and new knowledge. We can even see the application of this principle in agriculture:

(Source: Nassim Nicholas Taleb, Antifragile)
In Ireland, the English forced the conquered natives to specialize in a single crop, potatoes. Even worse, the forced their tenant farmers to focus on a single variety that the landlords thought especially suitable to the climate. This tactic produced great yields... until a blight hit the potato crop, and since the potatoes were all one variety, it wiped out most of the whole crop, for several years in a row. As Wikipedia has it:
"The widespread dependency on this single crop, and the lack of genetic variability among the potato plants in Ireland and Europe (a monoculture), were two of the reasons why the emergence of Phytophthora infestans had such devastating effects in Ireland and in similar areas of Europe." (Wikipedia.
Or, to put it in our terms, because the English has forced on Ireland this monoculture, the Irish lacked optionality: the ability to fall back on other options should one's primary strategy be blocked or fail.

(Source: Nassim Nicholas Taleb, Antifragile)
Other Material
- The Three Ways of DevOps
- Lean development principles
- Agile development principles
- Agile Technical Practices
- Software Development as a Discovery Procedure
- The Fallacies and Truths of DevOps
- Failed and Overbudget Software Projects
Although the Agile principles are great, some people have questioned how it is being applied, especially when it comes to the "Scrums" that so often characterize Agile practice. Here are some critics of Scrums: